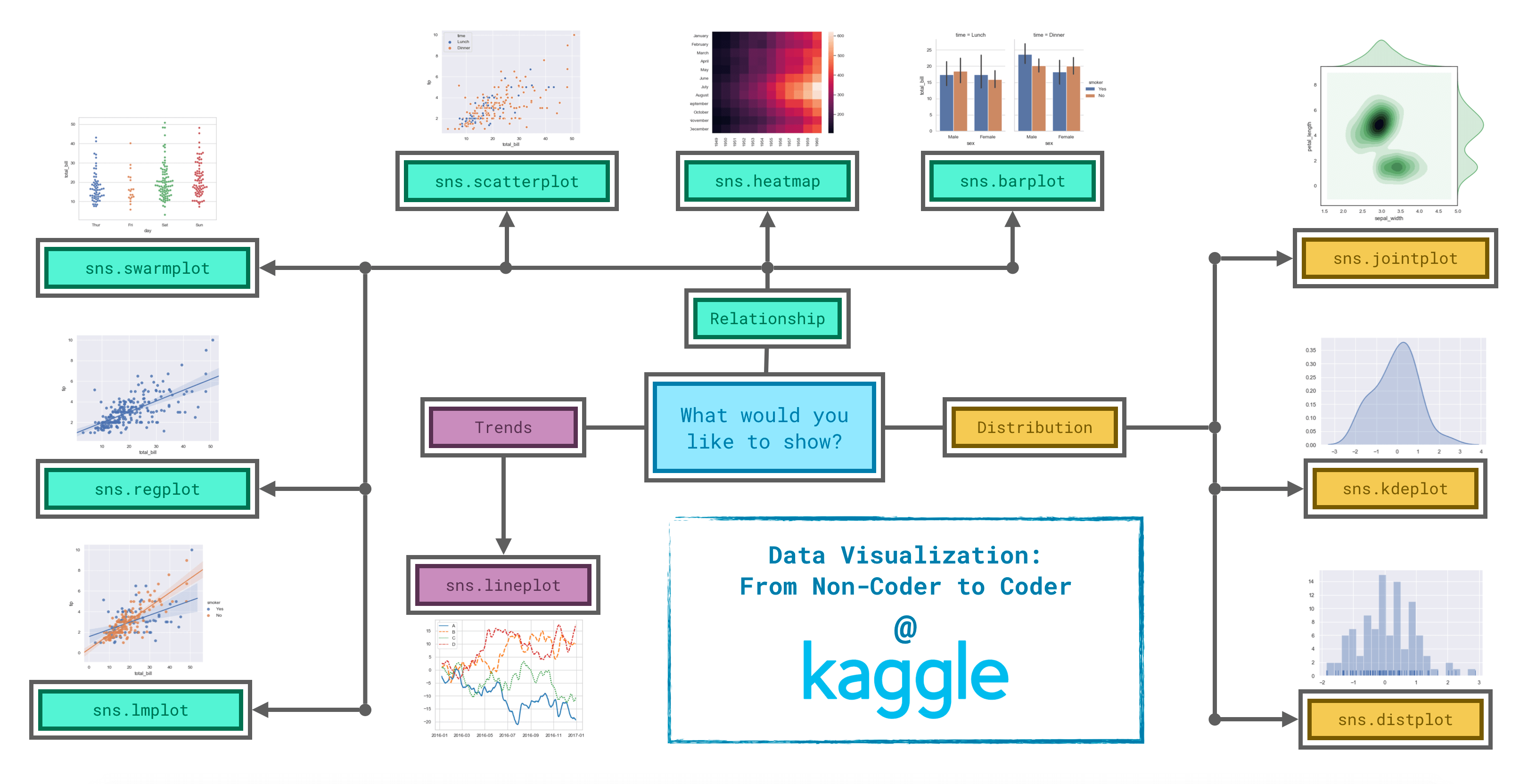
这是Seaborn数据可视化的思维导图,以后可以多回来看看作为参考。
在这篇博客中,我将简要介绍
全局环境
Seaborn依赖Pandas和Matplotlib库,所以我们先导入Pandas、Matplotlib和Seaborn库:
1
2
3
| import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
|
有时候我们的数据中有日期数据,我们希望可视化图表可以按照日期先后显示,如图:
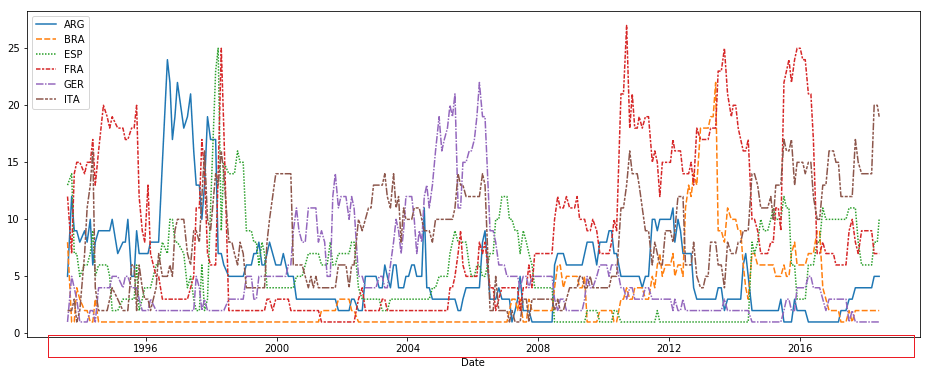
那么我们就需要配置Pandas绘图日期转写:
1
| pd.plotting.register_matplotlib_converters()
|
如果使用Jupyter Notebook,我们可能还希望配置Matplotlib显示方式。
1
2
| %matplotlib -l # 查看可用的显示方式
%matplotlib <显示方式> # 设置显示方式
|
数据导入
首先我们需要将数据转为CSV格式。虽然Pandas支持Excel格式的数据导入,但是Excel本身有太多其他功能数据,因此我们获取到的东西和我们在Excel中看到的并不一样。我们需要在Excel中另存为CSV格式,如图:
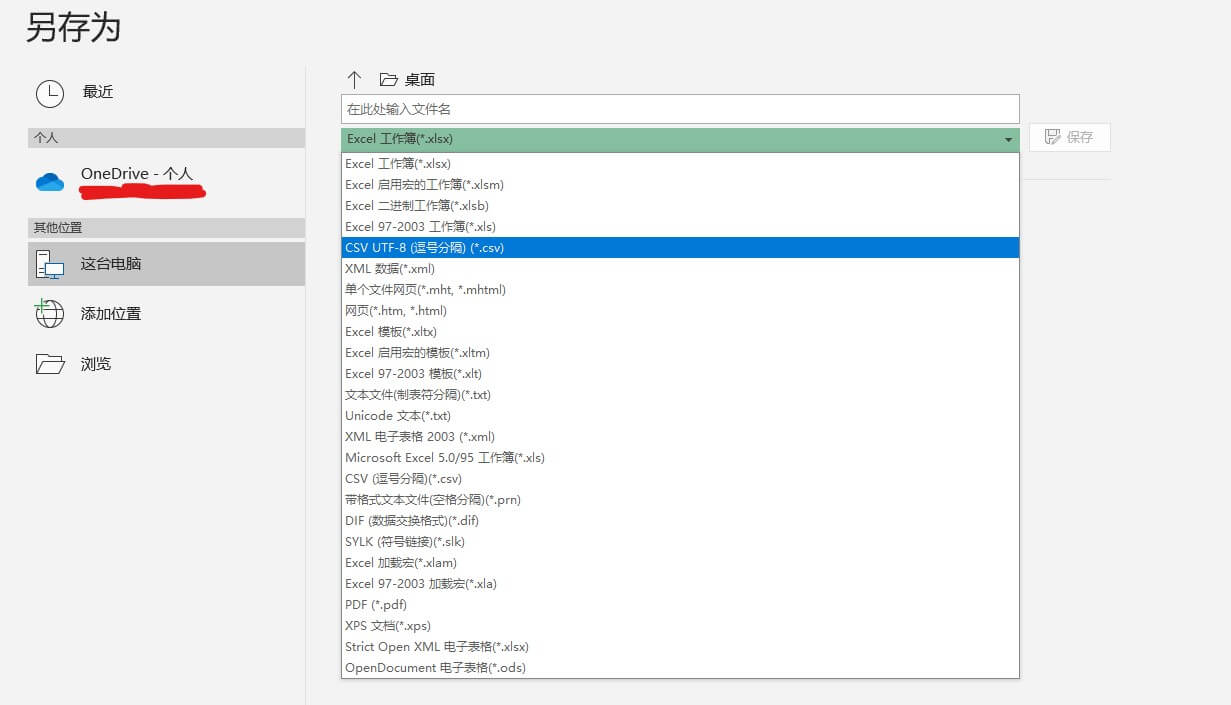
然后在Pandas中导入这个CSV文件:
1
2
| my_file = '<文件名>.csv'
my_data = pd.read_csv(my_file , index_col='<索引列列名>, parse_dates=True)
|
后面两个参数可选。index_col用于指定索引列,默认为首列;parse_dates用于解析日期,也就是Pandas绘图日期转写。
导入数据后可以浏览下数据的大概
1
2
3
| my_data.head(<行数>) # 查看导入的前几行,不指定即为5
my_data.tail(<行数>) # 后几行,不指定即为5
my_data.describe() # 查看求和、平均值、N分位数等数据统计信息
|
环境全局配置
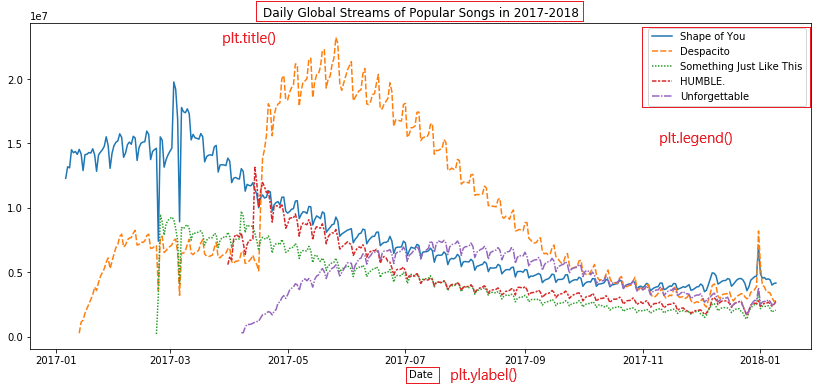
先配置Matplotlib画布信息(其实不配置也可以的):
1
2
3
4
5
| plt.figure(figsize=(<长>, <宽>)) # 设置画布尺寸,均为正整数,这是个玄学
plt.title('<图表标题>')
plt.xlabel('<X轴标题>')
plt.ylabel('<y轴标题>')
plt.legend() # 显示图例
|
如图所示:
然后配置Seaborn风格:
1
| sns.set_style('<风格名>')# 其中风格名包括darkgrid、whitegrid、ticks、dark、white
|
其实默认的就挺好看了,-grid的是带上网格的,dark-的是背景稍微深色一点的,适合装逼。ticks好像和white区别不大。
参考链接:
- https://www.kaggle.com/learn/data-visualization
- https://seaborn.pydata.org/